#User Validator
#Parameters
To verify the potenial collaborator's profile, we'll check 5 parameters in their github profile:
- The percentage of pull requests by the user that were ultimately merged.
- The frequency of commits by the user in all repos
- The sum of number of forks of the repos the user has contributed to
- The sum of number of stars of the repos the user has contributed to
- The number of organizations the user is part of.
We source this data from the Github Events API, using an OAuth Token(which rate limits us to 60 requests per day. ) This data is in the form of a JSON file which we convert to CSV file for easier implementation of further algorithms.
#Justification
These parameters are critical proxies of the user's trustworthiness.
The number of pull requests being merged show whether the code written by the user has been trusted by owners of other repos. If the code is malicious, it will obviously be ignored by other repos too and his pull requests wont be merged. Therefore, we can use it as a proxy to determine if the user writes malicious or usable code.
The frequency of commits shows how active a user is while contributing to open source repos. It shows that he isnt some dormant user with a nefarious purpose but has commited and contributed to other repositories as well.
This parameter proxies the quality and popularity of the repos the user has contributed to. It shows that the repos the user is contributing arent some artificial repos made by himself or through fake accounts. By gauging the number of forks the repo has, we can estimate the popularity of the repo in the open source community. Contribution to more popular repos directly correlates to writing more trustworthy code.
Similar to the number of forks, the number of stars of a repo show how interested other forks are in using this repo. Contributing to such a repo means that the user's code is sought after and well maintained.
A large open source repository/package necessitate the formation of an organization on github. The more number of organizations a user is a part of, the more trustworthy he appears, since his code has been trusted by independent organizations around the world. It also proxies the user's standing and reputation in the open source community. We also check if he has ever been kicked out of an organization, as it shows major distrust and lack of security.
#Calculating the security score
We take critical values for these parameters from the organization to give them the flexibility of security needed.
Only if each parameter of the profile exceeds the critical value and the aggregate value surpasses a threshold, we declare the user as trustworthy. Else, we give a % chance of the user being malicious (on the basis of our ML algorithm on the parameters)
For every parameter, we apply the clustering algorithm to predict the % chance that the user is malicious.
#Clustering Algorithm
After sourcing this data, we use a machine learning based clustering algorithm.
We have implemented an unsupervised machine learning algorithm that inputs a training dataset (which in our case would be the commit history of the user, which we extract from his/her GitHub profile link) and output a clustering model that helps us segregate the commits of a user into malicious and not malicious ones.
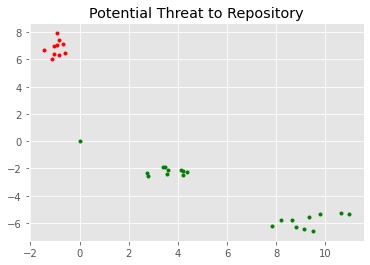
A malicious cluster is surrounded by the commits that our algorithm identifies as malicious and can possibly cause a major threat to the codebase.
A density based clustering algorithm (DBSCAN clustering algorithm) is implemented by us which finds the probabilities of commit results, classifies them as malicious or not malicious and finally aggregates them together.
This approach works well for locating outliers in a data set. Based on the density of data points in various places, it discovers clusters of arbitrary shape.
DBSCAN uses the minPts (the minimal number of data points that must be clustered together for an area to be considered high-density) and eps parameters to decide how clusters are defined (the distance used to determine if a data point is in the same area as other data points).
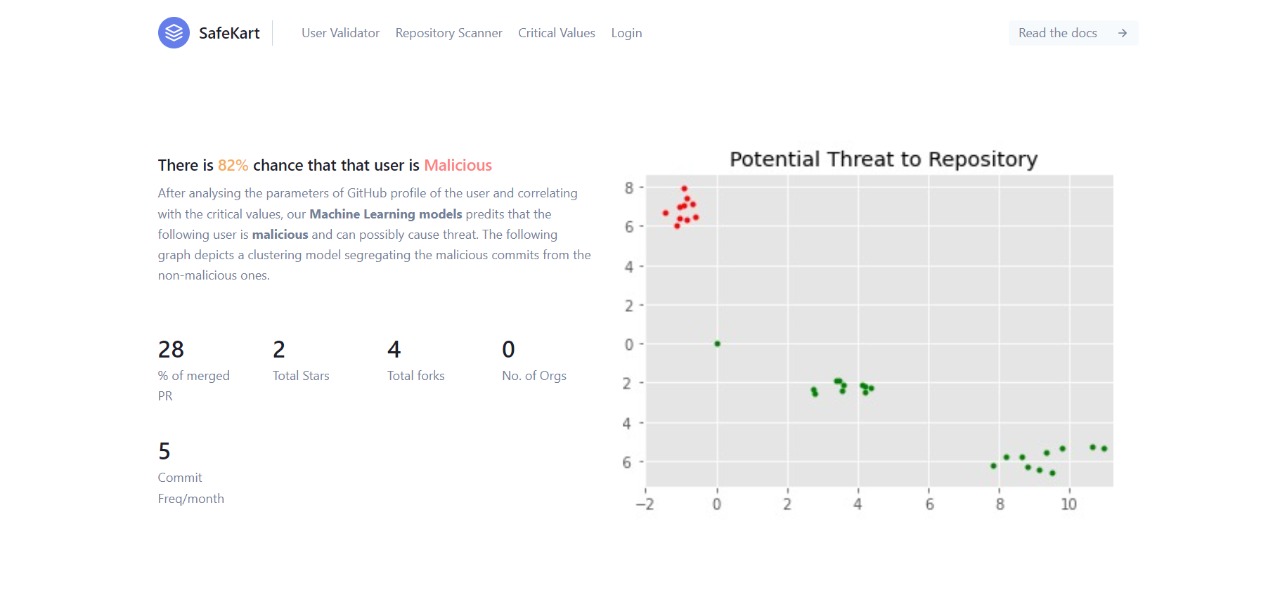
We have benchmarked line x = 0 for the diversification. All the points lying towards the left of x =0 line are classified as malicious commits and the ones to the right of line x=0 are not malicious commits.
Based on the relative count and accepted commit score standards, we come up with a final percentage of that user being classified into malicious or not malicious.
We take a weighted average of all the % scores of each paramater to calculate the final score (and the corresponding percentage) of the user being malicious or not.